Codescape Diaries: 01
In a world where everything is AI, I’m here building something that isn’t AI. Maybe that’s a mistake, but I’m going to try (and document the journey)!
I’ve been interested in code quality for a while. It’s something I think we talk a lot about, but struggle to actually define or measure in a good way. I wanted to take on that challenge and see what I could build.
This project started back in February 2025 when I did a kind of personal hackathon and built a POC of what this could look like.
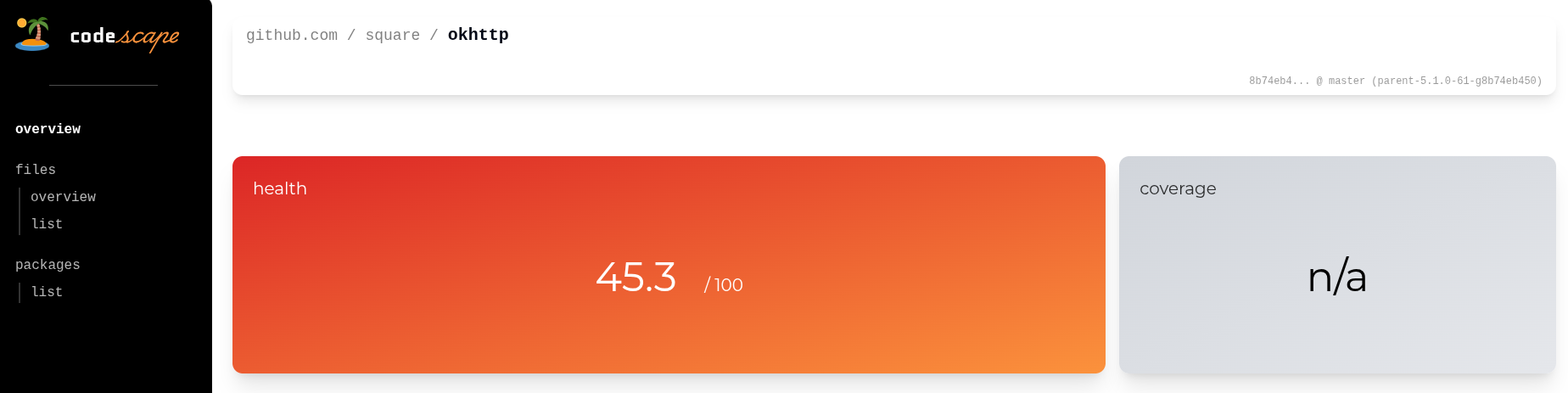
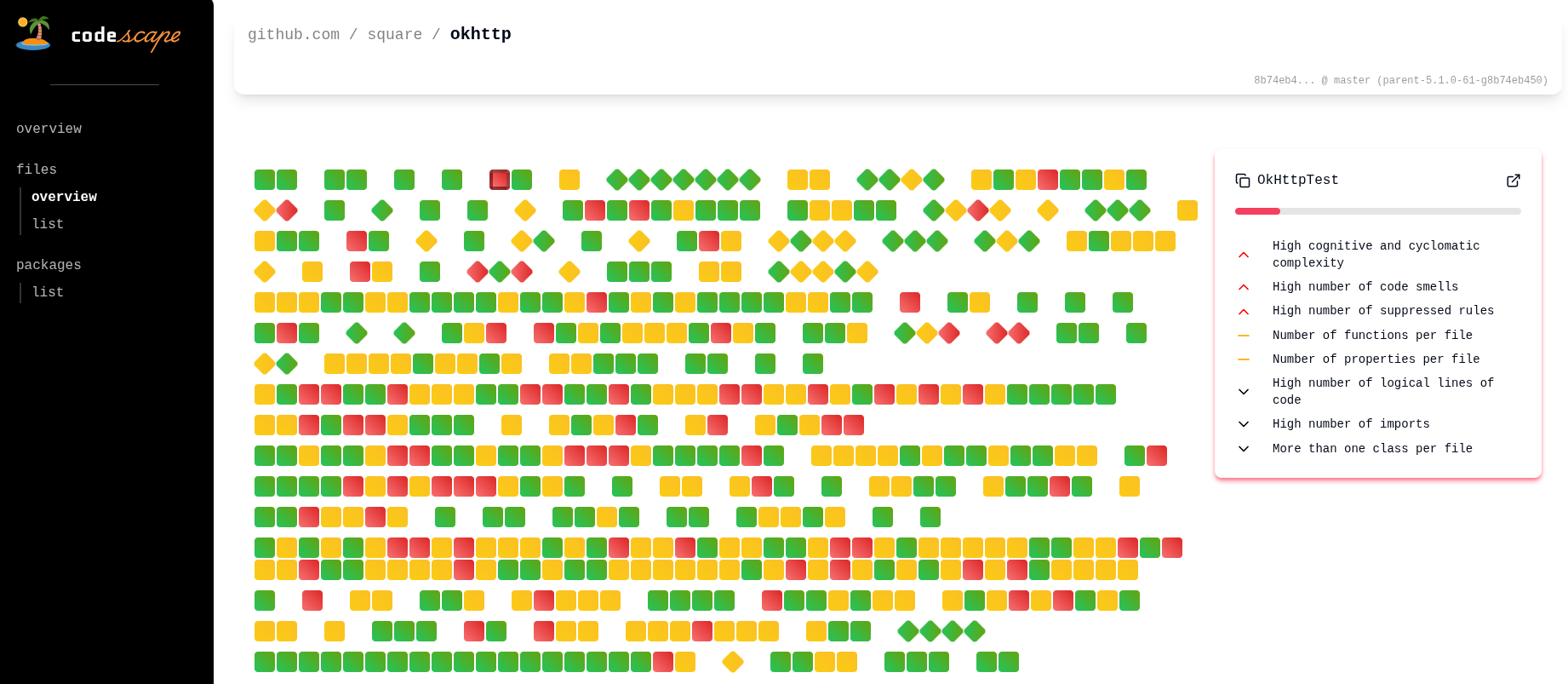
It was a fun exercise. I shared it with coworkers and it got people excited! So that gives me some confidence of the direction I’m going.
But as with any hackathon-like project, the idea I started with changed a lot by the time the POC was done, and the code was a bit of a mess 😅
So a few months later, now that ideas have had some time to brew (and other parts of my life have calmed down), I’m back to building this again. Maybe properly this time.
🗺️ Overview
So first things first, the design.
There are three parts to it:
- The collector
- The processor
- The UI
The previous approach only had a collector and the UI, but there are some benefits to splitting out the processor into it’s own thing:
- Makes the UI simpler and faster
- I no longer need to load the entire report to display it: I can split out data into smaller pieces to be loaded as needed
- The processing happens only once
- I can run the processor in the cloud somewhere and it only gets run once per report, not every time someone looks at the page
- Easier multi-langauge support
- I can create a new collector dedicated to that language instead of bundling in every possible language into the same collector
- I don’t even have to change the processor, the collectors just need to export data in the correct format
Another benefit is that I can make the processed data available for other processes. Things like exposing it via API or in a CLI script 👌
📌 Progress so far
So far I’ve been working on the kotlin collector. It’s probably the simplest part. This collector handles taking a project repository and collecting all the useful data about it and putting it into a massive .json file.
This includes some top-level information like the git branch and commit hash plus a lot of detailed info about the code that makes up the project.
So for v1 I’m processing each function, class, and file to gather:
- Code size (lines of code, characters, number of functions, etc)
- Complexity (cyclomatic and cognitive)
- Type & visibility (interface or class, public or private, etc)
And even the git change history for each file: I track every time the file changed, lines added/removed, when it was changed, and by whom.
My plan is that all this data will be aggregated up into different views (i.e. package/folder view) and combined to gather interesting insights (i.e. where the brittle code is: high complexity + lots of changes).
The building part has been fun. I’m using detekt to parse the code into objects I can query in my code. It’s an amazing project and has been invaluable to gather this data!
The main challenges I’ve faced were around making it go faaaast 🔥
At first it took a couple of minutes for a small project and a couple of hours for a large project like kotlin. Now even a massive project like Kotlin can be processed in a couple of minutes 👌
How? There were two main changes I did to accomplish this:
Coroutines
At first I was processing files one at a time, in order. But there was no need for this: the processing of each file is independent of the others. So I used coroutines to get them to run in parallel.
This alone cut down the time by an order of magnitude.
Front-load git metadata loading
At first I was loading the git history for each file. Something like:
git log --numstat -- path/to/file.ktWhile this was running I checked my process list. It was all git commands. The issue is that in repositories with a lot of commits (100k+) any git operation can take a long time (in the order of seconds). And I was doing 60k+ git log commands 😅
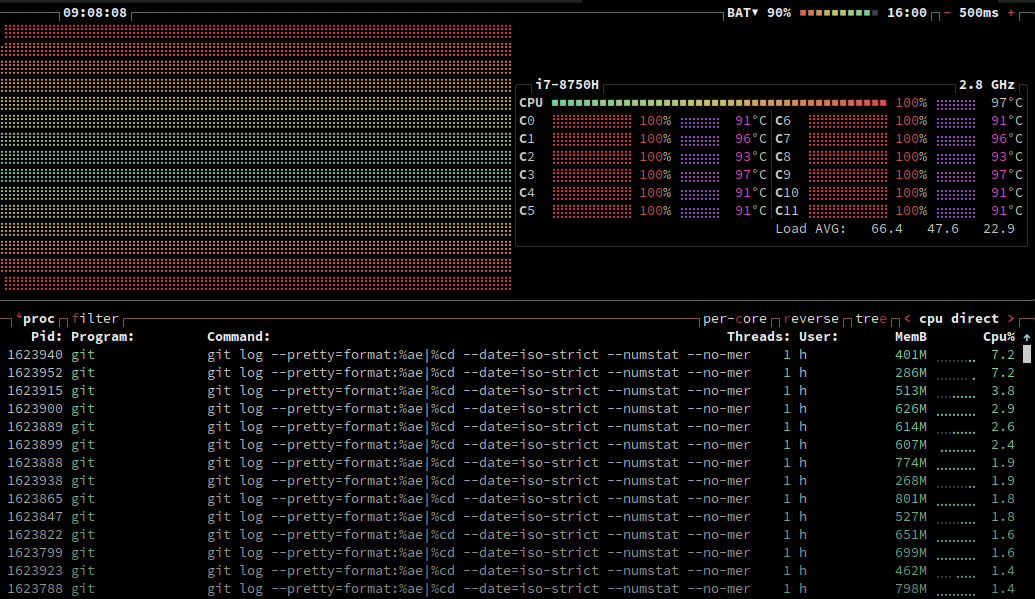
The obvious solution was to instead run a single command to load all this git data in one go. Something similar to above, but for all files, not just one:
git log --numstat -- *.ktThis takes a long time to run (in this case a couple of minutes), but it’s still orders of magnitude faster than doing it file-by-file. This brought the total time down from hours to minutes (or seconds for “normal” repositories!)
There was just one wrinkle though: renames.
Git does a pretty good job at tracking renames, but now I needed to handle them too. I’m linking the git history to the current file name, but the git command includes data for the old file names. So I was missing history data from before a rename.
In practice this meant that if you rename a file (or move it) I wasn’t able to track changes to that file from before the rename. So this would severely limit any features or insights that came from the git history.
Fortunately, tracking renames/moves myself wasn’t that complex. I made two changes. The first one was easy: reverse the history (I want to start processing at the beginning, not at the end). The second was a little harder: whenever I find a rename, move the existing history from the old name to the new name.
Renames in the git output have a pretty simple format: path/to/{some/path => new}/File.kt. This means that path/to/some/path/File.kt was moved to path/to/new/File.kt.
So as I’m going through the history I’m collecting all the changes made to path/to/some/path/File.kt, and when I find this entry I move that history over to path/to/new/File.kt. Once I reach the end of the history (the most recent commit) the file name in the history should match the one in the repository 🤞
⏩ Next?
I’m not 100% sure what I’m doing next. Obviously I’m going to set up the repositories for the UI and for the processor. Then I plan on building a single page with some relevant data (maybe total/avg/median complexity) and getting the full flow working for that piece. Then expand it as I add more data.
I’ll post something when that step is complete 👌
// the end